分享一款极简编译器的实现
什么是编译器
在 Babel 的官网赫然写着 "Babel is a JavaScript compiler"。 我们非常熟悉的 Babel 就是一种编译器,针对 JS 语言的编译器。
什么是编译器(Compiler)?
compiler也叫编译器,是⼀种电脑程序,它会将⽤某种编程语⾔写成的源代码,转换成另⼀种编程语⾔。
从维基百科的定义来看,编译器就是个将当前语⾔转为其他语⾔的过程,回到Babel上,它所做的事就是 语法糖之类的转换,⽐如ES6/ES7/JSX转为ES5或者其他指定版本,因此称之为compiler也是正确的, 换⾔之,像我们平时开发过程中所谓的其他⼯具,如:
- Less / Saas
- TypeScript / coffeeScript
- Eslint
都可以看到compiler的身影,也是通过这些⼯具,才使得⽬前的前端⼯程化能⾛⼊相对的深⽔区。
编译器的实现思路
一般编译器的,输入都是程序的源代码,经过词法分析拆解成 token 序列,经过语法分析生成 AST 结点树,通过对 AST 的转换处理生成目标代码格式,最后输出目标代码。
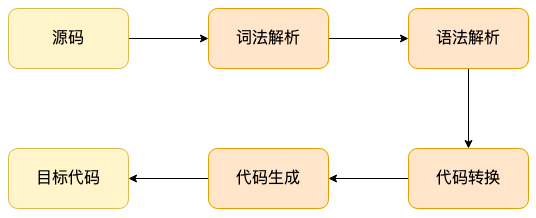
词法分析
将程序源代码分割成⼀个个的 “token”,例如:init、main、init、x、;、x、=、3、;、}等等。 同时去掉⼀些注释、空格、回⻋等等⽆效字符。token可以理解成最小的不可分的独立字符单元。 词法分析的目的,便于计算机理解一堆程序字符串的含义,是计算机认识程序的第一步。
词法分析⽣成token的方式有2种:
- 使⽤正则进⾏词法分析
需要写⼤量的正则表达式,正则之间还有冲突需要处理,不容易维护,性能不⾼,所以正则只适合⼀些简单的模板语法,真正复杂的语⾔并不合适。并且有的语⾔并不⼀定⾃带正则引擎。
- 使⽤⾃动机进⾏词法分析
状态机一般指有限状态机(英语:finite-state machine,缩写:FSM)又称有限状态自动机(英语:finite-state automaton,缩写:FSA),是表示有限个状态以及在这些状态之间的转移和动作等行为的数学计算模型。 有限状态机是在自动机理论和计算理论中研究的一类自动机。
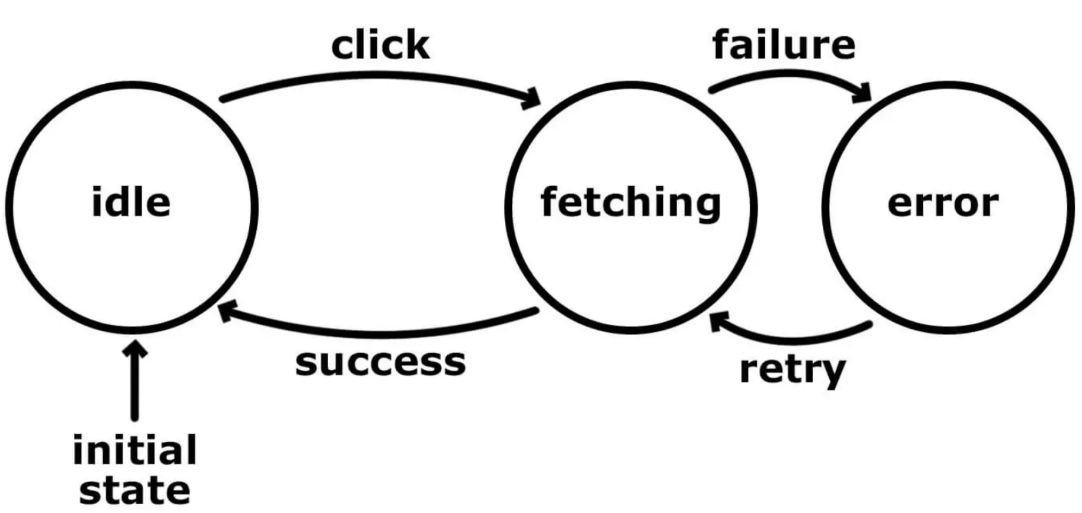
状态机中有几个术语:state(状态) 、transition(转移) 、action(动作) 、transition condition(转移条件) 。
有限状态⾃动机(finite state machine):在有限个输⼊的情况下,在这些状态中转移并期望最终达到终⽌状态。 有限状态⾃动机根据确定性可以分为:
- “确定有限状态⾃动机”(DFA - Deterministic finite automaton) 在输⼊⼀个状态时,只得到⼀个固定的状态。DFA 可以认为是⼀种特殊的 NFA;
- “⾮确定有穷⾃动机”(NFA - Non-deterministic finite automaton) 当输⼊⼀个字符或者条件得到⼀个状态机的集合。
JavaScript 正则采⽤的是 NFA 引擎,
语法分析
我们⽇常所说的编译原理就是将⼀种语⾔转换为另⼀种语⾔。 编译原理被称为形式语⾔,它是⼀类⽆需知道太多语⾔背景、⽆歧义的语⾔。 ⽽⾃然语⾔通常难以处理,主要是因为难以识别语⾔中哪些是名词,哪些是动词,哪些是形容词。 例如:“进⼝汽⻋”这句话,“进⼝”到底是动词还是形容词? 所以我们要解析⼀⻔语⾔,前提是这⻔语⾔有严格的语法规定,⽽定义语⾔的语法规格称为⽂法。
1956年,乔姆斯基将⽂法按照规范的严格性分为0型、1型、2型和3型共4中⽂法,从0到3⽂法规则是逐渐增加严的。 ⼀般的计算机语⾔是2型,因为0和1型⽂法定义宽松,将⼤⼤增加解析难度、降低解析效率,⽽3型⽂法限制⼜多,不利于语⾔设计灵活性。 2型⽂法也叫做上下⽂⽆关⽂法(CFG)。
语法分析的⽬的就是通过词法分析器拿到的token流 + 结合⽂法规则,通过⼀定算法得到⼀颗抽象语法树(AST,abstract syntax tree)。 抽象语法树是⾮常重要的概念,尤其在前端领域应⽤很⼴。 典型应⽤如babel插件,它的原理就是:es6代码 → Babylon.parse → AST → babel-traverse → 新的AST → es5代码。
从⽣成AST效率和实现难度上,前⼈总结主要有2种解析算法:⾃顶向下的分析⽅法和⾃底向上的分析⽅法。 ⾃底向上算法分析⽂法范围⼴,但实现难度⼤。 ⽽⾃顶向下算法实现相对简单,并且能够解析⽂法的范围也不错,所以⼀般的compiler都是采⽤深度优先索引的⽅式。
代码转换
在得到AST后,我们⼀般会先将AST转为另⼀种AST,⽬的是⽣成更符合预期的AST,这⼀步称为代码转换(transformation)。
代码转换的优势:主要是产⽣⼯程上的意义
- 易移植:与机器⽆关,所以它作为中间语⾔可以为⽣成多种不同型号的⽬标机器码服务;
- 机器⽆关优化:对中间码进⾏机器⽆关优化,利于提⾼代码质量;
- 层次清晰:将AST映射成中间代码表示,再映射成⽬标代码的⼯作分层进⾏,使编译算法更加清晰
对于⼀个Compiler⽽⾔,在转换阶段通常有两种形式:
- 同语⾔的AST转换;
- AST转换为新语⾔的AST;
这⾥有⼀种通⽤的做法是,对我们之前的AST从上⾄下的解析(称为traversal),然后会有个映射表(称为visitor),把对应的类型做相应的转换。
代码生成
在实际的代码处理过程中,可能会递归的分析(recursive)我们最终⽣成的AST,然后对于每种 type 都有个对应的函数处理,当然,这可能是最简单的做法。 总之,我们的⽬标代码会在这⼀步生成(generation)。
完成链路
⾄此,我们就完成了⼀个完整的 Compiler 的所有过程:
input => tokenizer => tokens; // 词法分析
tokens => parser => ast; // 语法分析,⽣成AST
ast => transformer => newAst; // 中间层代码转换
newAst => generator => output; // ⽣成⽬标代码input => tokenizer => tokens; // 词法分析
tokens => parser => ast; // 语法分析,⽣成AST
ast => transformer => newAst; // 中间层代码转换
newAst => generator => output; // ⽣成⽬标代码实现一个简单的编译器
背景介绍
要实现的编译器很简单,主要是为了理解其中的原理。 删除所有注释,这个⽂件只有⼤约 200 ⾏实际代码。 要实现的功能如下:
如果我们有两个函数 add 和 subtract 他们会写成这样:
- 2 + 2 (add 2 2) add(2, 2)
- 4 - 2 (subtract 4 2) subtract(4, 2)
- 2 + (4 - 2) (add 2 (subtract 4 2)) add(2, subtract(4, 2))
我们的目标是将(add 2 2)这样的LISP的写法,转换成C语言的写法 add(2, 2)。 这是我们的编译器要做的工作。
思路分析
⼤多数编译器分为三个主要阶段:解析、转换、和代码⽣成。 解析分为词法分析(Lexical Analysis)和语法分析(Syntactic Analysis)两个阶段。 在词法分析中,我们以(add 2 (subtract 4 2))为例,会生成下面的字符序列(Tokens)
[
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
][
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
]语法分析中,会将字符序列(tokens)转换成下面的形式,一颗AST(abstract syntax tree)结点树
{
type: 'Program',
body: [{
type: 'CallExpression',
name: 'add',
params: [{
type: 'NumberLiteral',
value: '2',
}, {
type: 'CallExpression',
name: 'subtract',
params: [{
type: 'NumberLiteral',
value: '4',
}, {
type: 'NumberLiteral',
value: '2',
}]
}]
}]
}{
type: 'Program',
body: [{
type: 'CallExpression',
name: 'add',
params: [{
type: 'NumberLiteral',
value: '2',
}, {
type: 'CallExpression',
name: 'subtract',
params: [{
type: 'NumberLiteral',
value: '4',
}, {
type: 'NumberLiteral',
value: '2',
}]
}]
}]
}转换阶段,我们会遍历上面生成的 AST 结点树,转换 AST 时,我们可以通过以下⽅式操作节点:
- 添加/删除/替换属性,我们可以添加新节点,删除节点,或者 创建⼀个全新的
所以对于上⾯的 AST,我们会去:
- Program - 从 AST 的顶层开始
- CallExpression (add) - 移动到程序主体的第⼀个元素
- NumberLiteral (2) - 移动到 CallExpression 参数的第⼀个元素
- CallExpression (subtract) - 移动到 CallExpression 参数的第⼆个元素
- NumberLiteral (4) - 移动到 CallExpression 参数的第⼀个元素
- NumberLiteral (2) - 移动到 CallExpression 参数的第⼆个元素
这里我们需要创建访问器(visitor)来遍历结点,创建一个访问器对象:
var visitor = {
NumberLiteral(node, parent) {},
CallExpression(node, parent) {},
};var visitor = {
NumberLiteral(node, parent) {},
CallExpression(node, parent) {},
};采用深度优先遍历的方式,访问 AST上的结点:
-> Program (enter)
-> CallExpression (enter)
-> Number Literal (enter)
<- Number Literal (exit)
-> Call Expression (enter)
-> Number Literal (enter)
<- Number Literal (exit)
-> Number Literal (enter)
<- Number Literal (exit)
<- CallExpression (exit)
<- CallExpression (exit)
<- Program (exit) -> Program (enter)
-> CallExpression (enter)
-> Number Literal (enter)
<- Number Literal (exit)
-> Call Expression (enter)
-> Number Literal (enter)
<- Number Literal (exit)
-> Number Literal (enter)
<- Number Literal (exit)
<- CallExpression (exit)
<- CallExpression (exit)
<- Program (exit)为了能及时退出当前结点,返回到上一层,增加退出时间的处理逻辑,需要改变一下访问器的结构:
var visitor = {
NumberLiteral: {
enter(node, parent) {},
exit(node, parent) {},
}
};var visitor = {
NumberLiteral: {
enter(node, parent) {},
exit(node, parent) {},
}
};代码生成
编译器的最后阶段是代码⽣成。 有时编译器会做与转换重叠的东⻄,但⼤部分情况下代码⽣成只是取出 AST结点树,并转换成字符串。 代码⽣成器(generator)根据结点类型转换成特定的字符串形式,然后递归调用,直到所有结点输出完成。
代码实现
词法分析
拆分成 token 序列
function tokenizer(input) {
let current = 0;
let tokens = [];
while (current < input.length) {
let char = input[current];
if (char === '(') {
tokens.push({
type: 'paren',
value: '(',
});
current++;
continue;
}
if (char === ')') {
tokens.push({
type: 'paren',
value: ')',
});
current++;
continue;
}
let WHITESPACE = /\s/;
if (WHITESPACE.test(char)) {
current++;
continue;
}
let NUMBERS = /[0-9]/;
if (NUMBERS.test(char)) {
let value = '';
while (NUMBERS.test(char)) {
value += char;
char = input[++current];
}
tokens.push({ type: 'number', value });
continue;
}
if (char === '"') {
let value = '';
char = input[++current];
while (char !== '"') {
value += char;
char = input[++current];
}
char = input[++current];
tokens.push({ type: 'string', value });
continue;
}
let LETTERS = /[a-z]/i;
if (LETTERS.test(char)) {
let value = '';
while (LETTERS.test(char)) {
value += char;
char = input[++current];
}
tokens.push({ type: 'name', value });
continue;
}
throw new TypeError('I dont know what this character is: ' + char);
}
return tokens;
}function tokenizer(input) {
let current = 0;
let tokens = [];
while (current < input.length) {
let char = input[current];
if (char === '(') {
tokens.push({
type: 'paren',
value: '(',
});
current++;
continue;
}
if (char === ')') {
tokens.push({
type: 'paren',
value: ')',
});
current++;
continue;
}
let WHITESPACE = /\s/;
if (WHITESPACE.test(char)) {
current++;
continue;
}
let NUMBERS = /[0-9]/;
if (NUMBERS.test(char)) {
let value = '';
while (NUMBERS.test(char)) {
value += char;
char = input[++current];
}
tokens.push({ type: 'number', value });
continue;
}
if (char === '"') {
let value = '';
char = input[++current];
while (char !== '"') {
value += char;
char = input[++current];
}
char = input[++current];
tokens.push({ type: 'string', value });
continue;
}
let LETTERS = /[a-z]/i;
if (LETTERS.test(char)) {
let value = '';
while (LETTERS.test(char)) {
value += char;
char = input[++current];
}
tokens.push({ type: 'name', value });
continue;
}
throw new TypeError('I dont know what this character is: ' + char);
}
return tokens;
}语法分析
解析生成 AST 结点树:
/**
* token 序列 => AST.
*
* [{ type: 'paren', value: '(' }, ...] => { type: 'Program', body: [...] }
*/
function parser(tokens) {
let current = 0;
function walk() {
let token = tokens[current];
if (token.type === 'number') {
current++;
return {
type: 'NumberLiteral',
value: token.value,
};
}
if (token.type === 'string') {
current++;
return {
type: 'StringLiteral',
value: token.value,
};
}
if (token.type === 'paren' && token.value === '(') {
token = tokens[++current];
let node = {
type: 'CallExpression',
name: token.value,
params: [],
};
token = tokens[++current];
while (
(token.type !== 'paren') ||
(token.type === 'paren' && token.value !== ')')
) {
node.params.push(walk());
token = tokens[current];
}
current++;
return node;
}
throw new TypeError(token.type);
}
// Now, we're going to create our AST which will have a root which is a
// `Program` node.
let ast = {
type: 'Program',
body: [],
};
while (current < tokens.length) {
ast.body.push(walk());
}
return ast;
}/**
* token 序列 => AST.
*
* [{ type: 'paren', value: '(' }, ...] => { type: 'Program', body: [...] }
*/
function parser(tokens) {
let current = 0;
function walk() {
let token = tokens[current];
if (token.type === 'number') {
current++;
return {
type: 'NumberLiteral',
value: token.value,
};
}
if (token.type === 'string') {
current++;
return {
type: 'StringLiteral',
value: token.value,
};
}
if (token.type === 'paren' && token.value === '(') {
token = tokens[++current];
let node = {
type: 'CallExpression',
name: token.value,
params: [],
};
token = tokens[++current];
while (
(token.type !== 'paren') ||
(token.type === 'paren' && token.value !== ')')
) {
node.params.push(walk());
token = tokens[current];
}
current++;
return node;
}
throw new TypeError(token.type);
}
// Now, we're going to create our AST which will have a root which is a
// `Program` node.
let ast = {
type: 'Program',
body: [],
};
while (current < tokens.length) {
ast.body.push(walk());
}
return ast;
}代码转换
function traverser(ast, visitor) {
function traverseArray(array, parent) {
array.forEach(child => {
traverseNode(child, parent);
});
}
function traverseNode(node, parent) {
let methods = visitor[node.type];
if (methods && methods.enter) {
methods.enter(node, parent);
}
switch (node.type) {
case 'Program':
traverseArray(node.body, node);
break;
case 'CallExpression':
traverseArray(node.params, node);
break;
case 'NumberLiteral':
case 'StringLiteral':
break;
default:
throw new TypeError(node.type);
}
if (methods && methods.exit) {
methods.exit(node, parent);
}
}
traverseNode(ast, null);
}
function transformer(ast) {
let newAst = {
type: 'Program',
body: [],
};
ast._context = newAst.body;
traverser(ast, {
NumberLiteral: {
enter(node, parent) {
parent._context.push({
type: 'NumberLiteral',
value: node.value,
});
},
},
StringLiteral: {
enter(node, parent) {
parent._context.push({
type: 'StringLiteral',
value: node.value,
});
},
},
CallExpression: {
enter(node, parent) {
let expression = {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: node.name,
},
arguments: [],
};
node._context = expression.arguments;
if (parent.type !== 'CallExpression') {
expression = {
type: 'ExpressionStatement',
expression: expression,
};
}
parent._context.push(expression);
},
}
});
return newAst;
}function traverser(ast, visitor) {
function traverseArray(array, parent) {
array.forEach(child => {
traverseNode(child, parent);
});
}
function traverseNode(node, parent) {
let methods = visitor[node.type];
if (methods && methods.enter) {
methods.enter(node, parent);
}
switch (node.type) {
case 'Program':
traverseArray(node.body, node);
break;
case 'CallExpression':
traverseArray(node.params, node);
break;
case 'NumberLiteral':
case 'StringLiteral':
break;
default:
throw new TypeError(node.type);
}
if (methods && methods.exit) {
methods.exit(node, parent);
}
}
traverseNode(ast, null);
}
function transformer(ast) {
let newAst = {
type: 'Program',
body: [],
};
ast._context = newAst.body;
traverser(ast, {
NumberLiteral: {
enter(node, parent) {
parent._context.push({
type: 'NumberLiteral',
value: node.value,
});
},
},
StringLiteral: {
enter(node, parent) {
parent._context.push({
type: 'StringLiteral',
value: node.value,
});
},
},
CallExpression: {
enter(node, parent) {
let expression = {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: node.name,
},
arguments: [],
};
node._context = expression.arguments;
if (parent.type !== 'CallExpression') {
expression = {
type: 'ExpressionStatement',
expression: expression,
};
}
parent._context.push(expression);
},
}
});
return newAst;
}代码生成
function codeGenerator(node) {
switch (node.type) {
case 'Program':
return node.body.map(codeGenerator)
.join('\n');
case 'ExpressionStatement':
return (
codeGenerator(node.expression) + ';'
);
case 'CallExpression':
return (
codeGenerator(node.callee) +
'(' + node.arguments.map(codeGenerator).join(', ') + ')'
);
case 'Identifier':
return node.name;
case 'NumberLiteral':
return node.value;
case 'StringLiteral':
return '"' + node.value + '"';
default:
throw new TypeError(node.type);
}
}function codeGenerator(node) {
switch (node.type) {
case 'Program':
return node.body.map(codeGenerator)
.join('\n');
case 'ExpressionStatement':
return (
codeGenerator(node.expression) + ';'
);
case 'CallExpression':
return (
codeGenerator(node.callee) +
'(' + node.arguments.map(codeGenerator).join(', ') + ')'
);
case 'Identifier':
return node.name;
case 'NumberLiteral':
return node.value;
case 'StringLiteral':
return '"' + node.value + '"';
default:
throw new TypeError(node.type);
}
}串联整个流程
function compiler(input) {
let tokens = tokenizer(input);
let ast = parser(tokens);
let newAst = transformer(ast);
let output = codeGenerator(newAst);
return output;
}function compiler(input) {
let tokens = tokenizer(input);
let ast = parser(tokens);
let newAst = transformer(ast);
let output = codeGenerator(newAst);
return output;
}对外提供API
module.exports = {
tokenizer,
parser,
traverser,
transformer,
codeGenerator,
compiler,
};module.exports = {
tokenizer,
parser,
traverser,
transformer,
codeGenerator,
compiler,
};